Introducción
Después que de que hemos entrado en la era de Bigdaddy, muchas de las reglas y estrategias que han usado los SEO´s en los últimos años para posicionar sus webs han perdido su validez.
A pesar de que posiblemente esta nueva infraestructura todavía esta en la fase de estabilización, parece que Google ya esta comenzando a realizar algunos experimentos para analizar sus resultados y en caso de ser satisfactorios podrían ser introducidos en el algoritmo ‘oficial’ del buscador
Esta idea se origina en la observación de los diferentes data centers (DCs) de Google en las ultimas semanas. En la era pre Bigdaddy, los ingenieros de Google realizaban sus pruebas solamente en algunos DCs y luego, después haber logrado sus objetivos, propagaban esos datos a los restantes DCs.
En las ultimas semanas se ha podido apreciar algo diferente: Se han observado diferentes series o clases de índices repartidos por todos los DCs. Por este motivo las posiciones de las páginas web han estado variando mucho, hasta el punto de que los foreros en WMW, expertos en el análisis de los DCs, han quedado totalmente desconcertados, ya que no han encontrado ningún concepto o teoría clara sobre el comportamiento de los DCs.
Análisis
Ahora bien, cómo se puede analizar correctamente el ranking o posición de una página web, suponiendo que Google esta usando diferentes índices en sus data centers, como resultado de la aplicación de diversos grupos o clases de algoritmos?
Después de haber observado la posición de muchas páginas web de varios proyectos, o mejor dicho dominios, en los diversos data centers de Google durante estos últimos meses, he llegado a las siguientes conclusiones:
Páginas web que pertenecen a dominios bien establecidos en Google y que poseen algún tipo de autoridad, han mantenido su ranking o posición en casi todos o todos los data centers.
Mientras que páginas que por uno u otro motivo todavía son débiles, o que estaban afectadas por alguno de los filtros de Google (poca antigüedad, contenidos duplicados, efecto sandbox, etc.) han estado variando continuamente de ranking en los data centers.
Eso significa entonces que páginas fuertes son estables a las posibles variaciones de los diferentes algoritmos de Google, mientras que las páginas débiles, son muy susceptibles a las variaciones de los algoritmos aplicados en los data centers.
Esta observación me lleva a definir un nuevo concepto: Estabilidad del Ranking de Google, o en ingles Google Ranking Stability (GRS).
El GRS es entonces una métrica que define la fortaleza o estabilidad de una página web en relación a los diferentes algoritmos que se pueden aplicar para generar un índice.
Si podemos calcular el GRS de una página, entonces sabemos cuan resistente es a los cambios algoritmicos que Google pueda introducir.
La siguiente tarea es entonces, encontrar un método para poder calcular el GRS de una página. Para esto necesario desarrollar una nomenclatura formal y una metodología de cálculo.
Nomenclatura
Para poder crear una herramienta formal que pueda calcular el GRS es necesario realizar algunas definiciones:
– d1,…,dn sean los data centers de Google
– u sea la url de una página web
– kw sean las palabras claves con las que se realiza una búsqueda.
Entonces,
pi[u|kw] es la posición de la página u para las palabras claves kw en el data center i.
– num sea el numero máximo de posiciones que el buscador de Google nos permite observar. Este valor actualmente es 100.
Con esto podemos fácilmente definir la posición promedio de una página u para las palabras claves kw en los n data centers de Google de la siguiente manera:
P[u|kw] = SUMA(pi[u|kw], 1,n) / n
El Google Ranking Stability (GRS) de la página u para las palabras claves kw lo definimos de la siguiente manera:
Sea
D[u|kw] = (MAX{p1[u|kw],…, pn[u|kw]}\{ pi[u|kw]>num} – MIN {p1[u|kw],…, pn[u|kw]}\{ pi[u|kw]>num})
Entonces tenemos
GRS[u|kw] = ((num – D[u|kw])*100)/num
La anterior formula la podemos explicar de la siguiente manera:
El término MAX{p1[u|kw],…, pn[u|kw]}\{ pi[u|kw]>num}
es el máximo de todas las posiciones pi[u|kw] de la página u para la búsqueda kw, pero sin tener en cuenta las posiciones mayores a num.
Mientras que el término MIN{p1[u|kw],…, pn[u|kw]}\{ pi[u|kw]>num}
es el mínimo de todas las posiciones pi[u|kw] de la página u para la búsqueda kw, pero sin tener en cuenta las posiciones mayores a num.
En palabras sencillas, esta parte de la formula nos da el ruido de las posiciones de la página u para la búsqueda kw en cada uno de los data centers. Pero como estamos definiendo la estabilidad, restamos de num este valor, y obtenemos:
Cuanto más grande es el valor de GRS, entonces mas estable es la página u para la búsqueda kw.
La herramienta
Para poder comprobar los resultados del Google Ranking Stability (GRS) he desarrollado una pequeña herramienta que ahora es de uso publico y se encuentra aquí.
Para finalizar este artículo deseo presentar algunos casos con la mencionada herramienta.
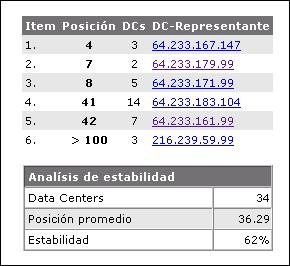
Caso 1: Página con poca estabilidad
La siguiente página tiene una gran variación en las posiciones (desde la 4. a la 42.) para la búsqueda kw en los diferentes DCs. Por eso, solo tiene un GRS de 62%
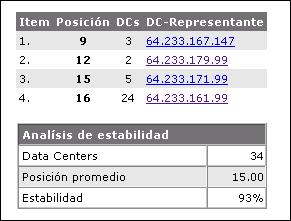
Caso 2: Página con una estabilidad media
La diferencia de las posiciones de esta página para kw en todos los DCs es relativamente pequeña (entre 9 y 16). Por este motivo su GRS ya es del 93%, mucho mas alto que en el primer caso.
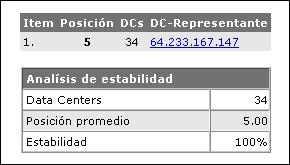
Caso 3: Página totalmente estable
En este ultimo caso, la posición de la página para la búsqueda kw es en todos los DCs la misma (posición 5). Esto significa que esta página es resistente a las variaciones de los algoritmos en los diferentes DCs.
Comentarios y opiniones sobre el tema son bienvenidos!