Cómo ya es bien conocido, el año pasado Google presentó su Buscador Universal, justamente en el mes de Mayo del 2007. Inmediatamente después, aparecieron en la red una serie de opiniones sobre las consecuencias que esto traería al tráfico de las páginas que aparecen en los resultados orgánicos del buscador. También aparecieron estudios por ejemplo sobre eye tracking en el buscador universal, pero al final la mayoría de los webmasters y SEOs se quedó tranquilo, ya que en la mayoría de las búsquedas no aparecían los mapas, imágenes o vídeos que pueden atraer la atención a los usuarios.
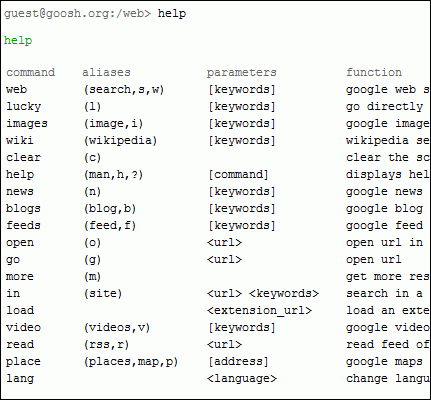
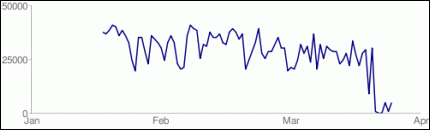
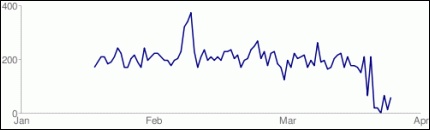
Pero ahora parece que Google si es lo ha tomado en serio, y como se comenta en un hilo de xeoweb muchos resultados para palabras muy competitivas aparecen en google.es llenas de imágenes, mapas, y otras componentes multimedia que atraen la atención de los usuarios y colocan en la sombra los resultados orgánicos del motor de búsqueda. Esto ha causado la pérdida de tráfico en las páginas que están en las primeras posiciones.
Dany Sullivan se ha dado el trabajo de clasificar todos los tipos de resultados que presenta el buscador universal de Google. Se trata de un artículo muy interesante en el que muestra detalladamente todos los tipos de búsquedas (web, book search, imagenes, local search, news, vídeo) y cómo han sido integrados en los resultados del buscador en los últimos meses. Todos los ejemplos se refieren a google.com.
Por ejemplo los mapas aparecían inicialmente en un formato grande, solamente con 3 referencias. Luego este mapa aparecía después de los 3 primeros resultados orgánicos y ahora esta apareciendo al inicio de la página de resultados un pequeño mapa, pero con 10 referencias (Justamente esto se comentaba en el hilo de xeoweb mencionado anteriormente).
Adicionalmente, Danny muestra también otros tipos de resultados que suelen aparecer.
Actualmente y según mis observaciones, este tipo de resultados se observan solamente para palabras claves muy competitivas y en dominios de Google para «países grandes». Mientras que los resultados para palabras o frases poco buscadas todavía son los antiguos.
Esto posiblemente se debe a que estas búsquedas no generan resultados en los servicios multimedia, de productos o noticias de Google; o que todavía no han sido integrados en el buscador universal; o finalmente Google no los piensa integrar y los mantendrá así.
Ahora, los webmasters van ha tener que generar el tráfico hacia sus webs usando los resultados de la cola larga o long-tail, o tratar de inscribir sus proyectos en maps, products, etc. Y esto con seguridad va ha generar mucho SPAM en estos servicios verticales.