Como ya es bien conocido, la mayoría de los servicios de webhosting limita el volumen de la transferencia de datos entre el servidor y los clientes en forma mensual. Este limite de transferencia depende de los paquetes que ofrecen y puede variar entre 1GByte y unos 15-20GByte por mes.
Si se ha contratado un paquete económico con volumen de tráfico limitado, entonces uno comienza a preocuparse cuando el tráfico en la web se incrementa considerablemente.
Este tráfico no solamente es generado por los visitantes de la web, sino también por los bots o robots de los diferentes motores de búsqueda y otros servicios que escanean la web.
Por ese motivo, y pensando en los webmasters Google hace poco mas de un año ha centralizado todos sus servicios de bots, como ser el googlebot, bot de imágenes, AdSense, news, etc. y ha creado en un cache centralizado de paginas web que puede ser usado por todos sus servicios. Solamente, en caso de que la página en el cache ya sea antigua o todavía no haya sido registrada salen los bots del servicio especifico a visitar la página requerida. De esta manera Google ha contribuido a disminuir el volumen de transferencia generado por los bots.
Pero a pesar de esto, muchas veces es necesario disminuir el volumen de transferencia de la web.
Ahora te presento una serie de procedimientos que te pueden ayudar:
1. Análisis
La meta principal para disminuir el volumen de transferencia es la reducción del tamaño de las páginas de la web. Aquí se debe considerar tanto el código HTML así como imágenes y otros componentes de multimedia.
Seleccionar las páginas que más trafico generan
No es necesario disminuir el tamaño de todas las páginas de una web, sino más bien solamente de las páginas que generan más trafico. Generalmente estas páginas hacen un 80% a 90% del tráfico total.
Para encontrar estas páginas, solamente se debe analizar los logs del servidor web u otras herramientas como Google Analytics.
Analizar los componentes de la página
Después de haber detectado y seleccionado las páginas con más tráfico, se debe analizar su tamaño, y el tipo de componentes que contienen.
Para esto, existen en Internet muchas herramientas que te pueden ayudar, como por ejemplo Web Optimization.
Esta herramienta muestra todos los tipos de objetos de la página, así como también sus tamaños, y los tiempos de descargas para diferentes velocidades de acceso, como se puede apreciar en la siguiente imagen:
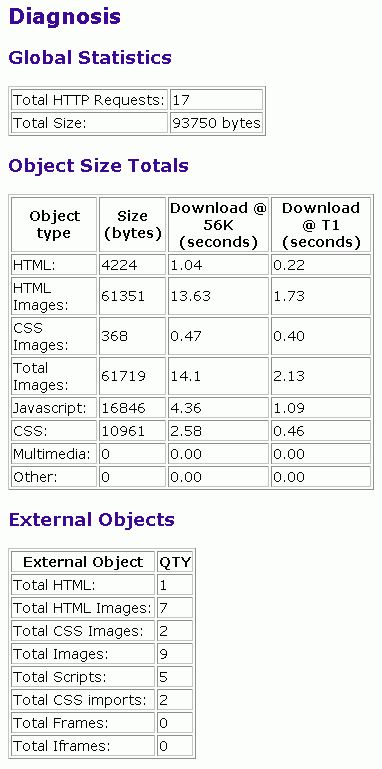
2. Optimización del tamaño de la página
Con el reporte anteriormente mencionado se puede comenzar a optimizar el tamaño de las páginas seleccionadas.
Imágenes
Una de las grandes sorpresas de este reporte, es que las imágenes hacen el grueso del tamaño de las páginas. Aquí, nuevamente, uno debe concentrar la atención solamente en las imágenes más pesadas.
Estas deben ser optimizadas con herramientas gráficas y/o modificando sus formatos. También se debe analizar la posibilidad de suprimir imagenes o por ejemplo remplazarlas con objetos css o atributos de color en HTML .
Código HTML
A pesar de que el código HTML generalmente es mucho más pequeño que las imágenes y objetos multimedia, es muy importante generar un archivo de HTML compacto por los siguientes motivos:
- Descarga y rendering rápidos Si el código HTML es pequeño, la página puede ser descargada y visualizada rápidamente por los navegadores. Luego, las imágenes y los otros componentes se van descargando poco a poco. Este efecto causa en el usuario la impresión de que la web es rápida y lo anima a continuar navegando.
- Reduce el volumen de transferencia de los bots Generalmente los robots de los buscadores se interesan solamente por el texto de la página y por eso solo leen el código HTML. Si este código es pequeño, el volumen de transferencia usado por los robots puede disminuir considerablemente. En muchos casos, esto también podría mejorar la frecuencia de las visitas de los bots.
El tamaño del código HTML se puede optimizar de muchas maneras:
Generar código compacto
Se deben evitar en el código los espacios y los cambios de carril (carridge return) , se debe usar nombres cortos para los identificadores de las clases y otros objetos. Por ejemplo, en vez de usar un identificador como ClasseDeCabecera se podría usar la abreviación cdc. El mejor ejemplo para aprender como optimizar el código HTML es leer el código fuente de las páginas de Google.
También se debe evitar en lo posible colocar comentarios en el código. En varios casos, he comprado que quitando los comentarios de una página – por ejemplo mediante un pequeño script que lea el código HTML y quite todos los comentarios antes de enviaro al cliente – se puede ahorrar unos 2 a 3 KBytes por página.
Si se asume por ejemplo, que esa página es descargada 10.000 veces al día, entonces se puede lograr un ahorro de unos 29,29 Megabytes de tráfico por día.
Comprimir el código HTML
Si se usa PHP para generar las páginas web, existe la posibilidad de comprimir el código HTML y enviarlo así al cliente. Los navegadores o browsers de ultima generación reconocen este código comprimido y lo descomprimen para visualizarlo. Por ejemplo, si un archivo HTML tiene unos 50 KB en estado normal, su tamaño comprimido es de unos 7 a 8KBytes que son los que realmente se transmiten desde el servidor web hasta el cliente. Esto significa nuevamente un gran ahorro en el volumen de transferencia de los datos.
El código en PHP que se debe colocar al inicio de cada página es el siguiente:
En caso de que el servidor web tenga la extensión zlib habilitada, el código generado (output) es comprimido antes de ser enviado al cliente.
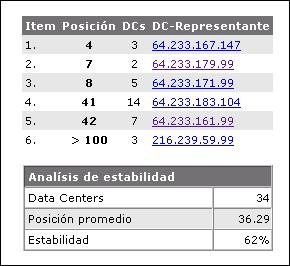
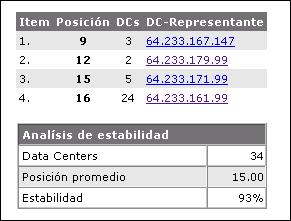
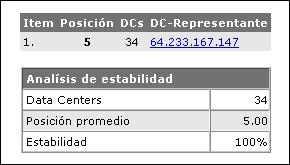
Un ejemplo claro del resultado que ha causado el uso de compresión en uno de mis proyectos se lo puede observar en la siguiente imagen:
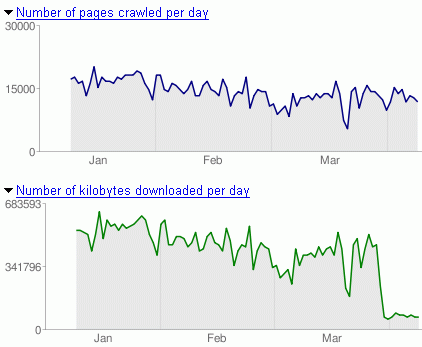
Después de que la compresión del código HTML fue habilitada, el volumen descargado diariamente por los bots de Google se ha reducido considerable, mientras que el número de páginas escaneadas no ha disminuido.
El otro efecto positivo de esta compresión ha sido que la carga del servidor ha disminuido considerablemente a pesar de que el numero de visitas no ha caido. Esto se debe a que que la cantidad de paquetes de datos transmitidos entre el servidor y el cliente ha disminuido también.
3. Conclusiones
Como se puede observar, el incremento del tráfico en una web, no necesariamente debe obligar a contratar un paquete con mas transferencia que siempre resulta ser más caro.
Lo que primero se debe hacer es analizar el origen del problema, y en caso de poder optimizar el tamaño de las páginas se lo debe realizar con todos los métodos explicados anteriormente.
La reducción del tamaño de las páginas tiene también otra ventaja adicional: El usuario percibe una mejor usabilidad lo que puede llevar a mejorar el tiempo de permanencia en la web y también a aumentar el numero de las visitas.